공유하기
AI를 알면 AI가 과장된 것도 안다[송평인의 시사서평]
- 동아일보
-
입력 2025년 7월 20일 10시 38분
글자크기 설정

지금은 대중매체에서 AI가 딥러닝(deep learning)을 뜻하는 것처럼 쓰이고 있지만 정확하지 않다. AI 연구는 지능을 가진 기계를 목표로 하는 모든 연구를 지칭한다. 그런 의미의 연구는 1956년 존 매카시(John McCarthy)라는 당시 29세의 젊은 수학자가 다트머스 대학에서 조직한 작은 워크샵에 기원을 두고 있다. 매카시는 프린스턴 대학원에서 만난 마빈 민스키(Marvin Minsky)와 의기투합해 2달간 10명의 모임을 주도했다. AI라는 말 자체를 만든 사람이 바로 매카시다.
처음 30년간 AI 연구를 지배한 것은 상징적(symbolic) AI 연구다. 예를 들어 3명의 선교사와 3명의 식인종이 있는데 선교사들이 식인종들에게 먹히지 않고 강 한편에서 다른 편으로 옮겨가는 방법 등을 찾는 것과 같은 연구다. 대표적 프로그램은 오늘날 글로벌 포지셔닝 시스템(GPS)에게 이름을 뺏긴 ‘범용 문제 해결자(General Problem Solver)라는 또 다른 GPS였다. 상징적 AI 연구는 컴퓨터가 지능을 얻기 위해 인간 두뇌를 모방할 필요가 있다고는 여기지 않았다.
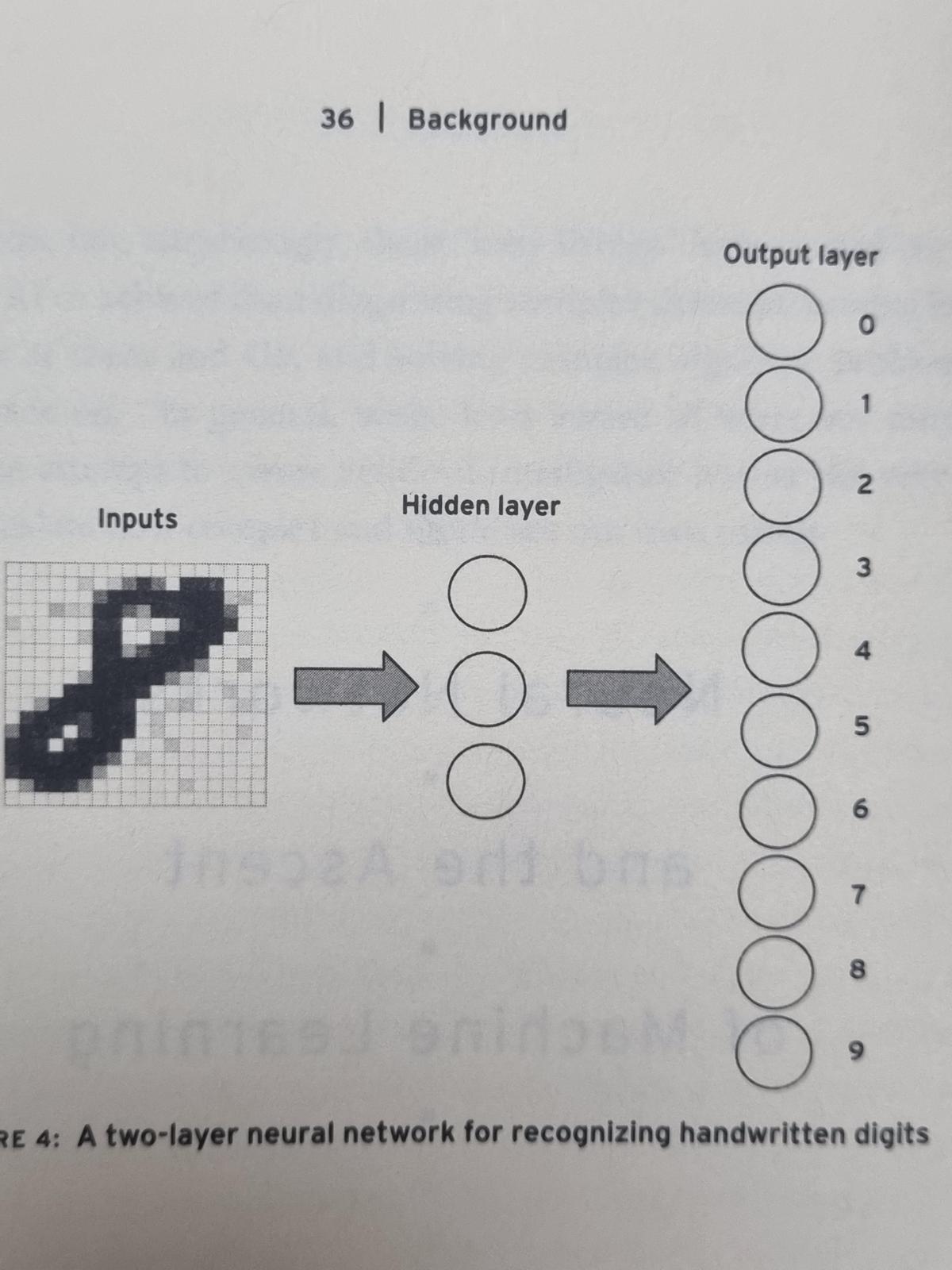
퍼셉트론은 손으로 쓴 숫자 등을 인식하는데 활용됐다. 가령 손으로 쓴 8이란 숫자에 사각형 테두리를 치고 사각형 속을 가로 18줄, 세로 18줄 등 모두 324개의 픽셀로 구분한 뒤 픽셀이 밝으면 0, 어두우면 1로 해서 플러스(+)와 마이너스(-)의 가중치를 곱한 뒤 그 합이 일정 선(threshold)을 넘으면 8인 걸로, 그렇지 않으면 8이 아닌 걸로 구별한다. 중요한 점은 행동심리학자 B.F.스키너처럼 결과에 따라 긍정적 보상과 부정적 보상을 하는 것이다. 8을 올바로 구별하지 못하면 가중치와 합격선을 조정하는 오차 역전파(back-propagation)을 하는데 신뢰도가 높아질 때까지 이 과정을 반복한다. 오늘날 강화학습 혹은 지도학습(supervised learning)이라고 불리는 것의 원초적 형태다.
로젠블랫이 퍼셉트론 개발에 박차를 가하고 있던 1960년대 초반 AI 연구의 4대 거물인 MIT의 마빈 민스키, 스탠포드의 존 매카시, 카네기 멜론의 허버트 사이몬(Herbert Simon)과 앨런 네웰(Allen Newell) 등은 모두 퍼셉트론에 부정적이었다. 특히 민스키는 1969년 ‘퍼셉트론들(Perceptrons)’란 책에서 퍼셉트론이 완벽히 풀 수 있는 문제의 유형은 아주 제한적이라고 주장했다. 물론 두뇌의 신경망을 모방한 층(layer)가 단층이 아니라 다층으로 이뤄진다면 활용 범위가 넓어질 것으로는 봤지만 이 점을 깊이 있게 다루지 않았다. 민스키 주장의 냉각효과로 AI 연구는 빙하기를 맞았다. 민스키는 ‘가장 쉬운 것이 어렵다(Easy things are hard)’라는 유명한 말을 남겼다. AI의 본래 목표는 어린아이도 할 수 있는 쉬운 것부터 하자는 것이었으나 그게 애초 예상만큼 쉽지 않았던 것이다.
오늘날 AI는 은닉층(hidden layer)을 가진 다층 신경망(multilayer neural network)으로 발전했다. 퍼셉트론처럼 픽셀의 값(입력값)을 사용해 단 한 번의 연산으로 출력값을 내는 게 아니라 입력과 출력 사이에 은닉층을 둬 단계를 거치도록 하는 것이다. 앞 선 필기체 인식을 다시 예로 들면 최초 입력값이 명암에 따른 것이라면 은닉층은 최초 입력값에 기초해 보다 추상적인, 가령 8이란 숫자의 경우 윗부분과 아랫부분에 둥근 형태가 있는지 등을 탐지해서 그 값을 다음 단계로 보내는 식이다. 그리고 결과값에서 오차 역전파를 통해 층위의 각 단계에서 가중치와 합격선을 조정함으로써 결과값의 신뢰도를 높인다.
마빈 민스키와 세이머 페이퍼트(Seymour Papert)는 컴퓨터의 시각 정보 인식을 돕기 위해 1966년부터 대학교 1학년생들을 모아 사진에 ‘여성’ ‘개’ 같은 카테고리를 달도록 하는 아르바이트를 시켰으나 큰 진전이 없었다. 민스키의 말처럼 시각은 인간에게는 가장 쉬운 것이었으나 컴퓨터에는 가장 어려운 것 중 하나였다. 개로 예를 들면 컴퓨터가 인식하는 것은 개 이미지의 픽셀일 뿐이다. 개를 개 아닌 것과 구별해야 하고 개에도 많은 종류의 개가 있다.
그러나 이미지에서 물체를 인식하는 능력은 2010년대에 이르러 딥러닝으로 비약적인 발전을 이뤘다. 딥러닝은 정확히는 심층 신경망(deep neural network)을 의미한다. 신경망의 깊이는 얕을(swallow) 수도 있고 깊을(deep)을 수도 있다. 깊다고 하는 것은 신경망에서 은닉층이 많다는 뜻이다. 은닉층이 수백 개, 수천 개에 이를 수도 있다.
●컴퓨터 신경망은 두뇌처럼 겹으로 돼 있다.
민스키가 학생들에게 고생스런 아르바이트를 시키고 있을 때 데이비드 허블(David Hubel)과 토르스텐 비셀(Torsten Wiesel)이라는 2명의 신경과학자가 두뇌의 시각작용에 대한 이해에 진전을 이뤄 나중에 노벨상을 받았다. 눈이 물체를 볼 때 받아들이는 것은 그 물체에 반사된 빛이다. 이 빛이 망막의 세포를 활성화시키면 그 활동이 신경을 통해 뇌에 전달돼 머리 뒤쪽에 있는 신경 피질의 세포를 활성화시킨다. 신경 피질은 여러 겹의 신경 세포가 케이크 쌓여 있고 각 층의 신경 세포의 활성화가 그 다음 층으로 전달되는 계층구조를 이루고 있다. 두 신경과학자의 발견은 일본 엔지니어 후쿠시마 쿠니히코가 1870년대에 최초의 심층 신경망을 개발하는데 영감을 줬다. 바로 이것이 코그니트론이고 그 후속이 네오코그니트론이다. 네오코그니트론은 오늘날 가장 널리 쓰이는 딥러닝 프로그램인 합성곱 신경망(convolutional neutral network)에 중요한 영감을 줬다.
우리는 합성곱 신경망을 사용한 ConvNet을 일상에서 쉽게 실험할 수 있다. 어느 물체의 사진을 찍은 뒤 구글에서 업로드한 뒤 ‘이미지로 찾기(search by image)’를 작용시키면 구글이 그 이미지에 대해 ConvNet을 작동시켜 수천개의 카테고리별 결과 신뢰도에 따라 최고의 추정(best guess)을 알려준다.
ConvNet을 훈련시키려면 개와 고양이에 대한 많은 표본 이미지를 수집해야 하고 각각의 이미지에 개인지 고양인지 라벨을 붙인 파일을 만들어야 한다. 처음에는 무작위 가중치를 부여하고 결과값에 따라 가중치를 조정한다. 이 과정을 에포크(epoch)라고 한다. ConvNet을 훈련시키려면 많은 에포크를 반복해야 한다.
ConvNet의 발명자는 얀 르컹(Yann LeCun)이다. 그는 후쿠시마의 네오코그니트론에는 강화학습 알고리듬이 부족하다는 점을 발견하고 ConvNet의 최초 버전인 르넷(LeNet)을 개발했고 조프리 힌턴(Geoffrey Hinton)과 함께 오늘날 ConvNet에 사용되는 오차 역전파의 형식을 개발했다.
ConvNet과 같은 시각 정보 처리 프로그램이 발전하기 위해서는 민스키가 대학생을 고용해 카테고리별 라벨을 달도록 하는 작업이 필요했다. 아마존의 메커니컬 터크(Mechanical Turk) 서비스가 그 역할을 했다. 세계 각국에서 적은 비용으로 사진에 라벨을 달아주는 수 만 명의 사람들과 계약을 맺었다. 컴퓨터가 하기에 너무 어려웠지만 사람이 하기는 쉬운 일이었다..
이런 라벨링 작업의 결과로 2010년 최초의 거대 규모 시각 인식 대회가 열렸는데 이것을 이미지넷(ImageNet) 대회라고 한다. 2012년 대회에서 알렉스넷(AlexNet)이라고 불리는 ConvNet이 85%의 놀라운 정확도로 1등을 차지했다. 알렉스넷은 당시 토론토 대학 대학원생인 알렉스 크리제프스키가 만들고 조프리 힌턴에 의해 강화학습된 프로그램으로 얀 르컹의 르넷의 발전된 버전이다. 이후 1년만에 조프리 힌턴이 만든 작은 회사가 구글에 인수됐고 힌턴과 학생들은 구글에 채용됐다. 이 인수합병이 구글을 딥러닝의 선두주자로 만들었다. 얼마 후 얀 르컹은 뉴욕대 교수에서 페이스북으로 자리를 옮겨 AI 랩을 이끌었다. ConvNet의 골드러시라고 부를 만한 현상이다. 딥러닝으로 훈련된 ConvNet으로 인해 구글 마이크로소프트 등의 이미지 검색 엔진의 성능은 급격히 향상됐다. 또 ConvNet에 의해 요구된 확장된 훈련은 강력한 그래픽카드(GPU)를 가진 전문화된 컴퓨터 하드웨서에서만 가능했기 때문에 가장 저명한 GPU 제조사인 엔디비아의 주가가 2012년에서 2017년 사이 1000% 이상 치솟았다.
●컴퓨터는 여전히 인간처럼 보지 못한다
2017년 이미지넷 대회에서 ConvNet의 정확도는 98%까지 올라갔다. 사람도 물체 인식에서 약 5%의 실수를 한다. ConvNet의 실수율이 2%라면 물체 인식에서 컴퓨터가 인간을 앞지른 것인가. 오해해선 안된다. 이미지넷 대회에서 98%의 정확성이란 농구의 이미지를 제시했을 때 컴퓨터가 제시하는 다섯 개의 카테고리 속에 농구가 포함될 확률이 98%라는 뜻이다. 한 개의 카테고리만으로 측정하면 정확도는 82%로 확 떨어진다. 또 단순한 분류를 넘어 그 물체가 사진 속 어디에 위치하는지 특정하라고 물으면 정확도가 더 떨어진다.
사실 인간과 컴퓨터의 물체 인식의 차이를 이 정도의 비교를 훨씬 넘어선다. 물체 인식은 단순한 시각 정보 이상을 의미한다. 만약 목표가 컴퓨터가 보고 있는 것을 설명하는 것이라면 단순히 물체를 인식하는 걸 넘어 물체들의 관계를 인식해야 한다. 물체들의 관계를 인식한다는 것은 언어를 사용해서 표현할 수 있다는 것을 의미한다. 인간이 갖고 있는 비주얼 인텔리전스(visual intelligence)로부터 컴퓨터는 여전히 멀다.
무엇보다 컴퓨터의 학습은 인간의 학습과 다르다. 컴퓨터가 스스로 배운다는 말을 정확한 표현이 아니다. 컴퓨터의 강화 학습은 주어진 카테고리의 범주에서 이뤄진다. 그러나 아이들의 카테고리의 목록은 개방돼 있다. 그들은 수동적으로 배우는 것이 아니라 적극적으로 배운다. 질문하고 정보를 요구하면서 열린 목록을 채워간다. 또 단지 몇 개의 실례로부터 추상해서 카테고리를 알아내고 물체들 사이의 관계도 파악한다.
딥러닝은 빅데이타를 요구한다. 수백만장 이상의 라벨이 붙은 훈련 이미지가 필요하다는 의미에서 ‘빅(big)‘이다. 저명한 AI 연구자 앤드류 응(Andrew Ng)은 “많은 정보를 요구하는 것이 딥러닝의 한계”라고 말한다. 또 다른 저명한 AI 연구자인 요슈야 벤지오는 “우리는 현실적으로 세상의 모든 것에 라벨을 달 수 없다”고 말한다. 이들이 제기하는 것은 롱 테일(long tail)의 문제다.

자율주행차가 마주할 여러 가정적 상황의 가능성이 다 다르다. 붉은 신호등이나 정지 사인을 마주하는 상황은 하루에도 수십 번이 되고 깨진 유리나 바람에 날리는 비닐봉투를 마주하는 상황은 매일은 아니지만 간혹 가다가 있을 수 있지만 홍수로 물이 범람한 도로나 눈 때문에 차선이 흐려진 경우는 드물다. 현실 세계의 사건은 대체로 예측 가능하지만 그럼에도 늘 낮은 가능성을 가진 긴 꼬리 부분이 남아있다. 실제로 2016년 눈 예보 때문에 뿌린 소금으로 인해 차선과 함께 소금이 차에 끌려간 선이 함께 그려져 테슬라의 자율주행에서 혼돈을 초래했다. 롱 테일의 문제를 풀려면 지도되지 않은 강화 학습(unsupervised learning)이 필요하지만 아직까지 지도되지 않은 강화 학습의 성공한 사례가 없다. 얀 르컹은 “지도되지 않은 강화 학습은 AI의 암흑 물질(dark matter)”라고 말했다. 이런 학습은 추상과 비유의 능력을 필요로 하는데 컴퓨터는 갖고 있지 않다.
*책의 나머지 반은 컴퓨터의 언어 인식에 관한 내용이다. 글이 너무 길어졌기 때문에 나머지 반에 대해서는 다음 회에서 다루겠다.
송평인의 시사서평 >
구독
![AI와 달리 인간은 추상하고 비유한다[송평인의 시사서평]](https://dimg.donga.com/a/180/101/95/2/wps/NEWS/IMAGE/2025/08/10/132156253.1.jpg)
이런 구독물도 추천합니다!
-

2030세상
구독
-
김승련 칼럼
구독
-

청계천 옆 사진관
구독
© dongA.com All rights reserved. 무단 전재, 재배포 및 AI학습 이용 금지
트렌드뉴스
-
1
‘건강 지킴이’ 당근, 효능 높이는 섭취법[정세연의 음식처방]
-
2
反美동맹국 어려움 방관하는 푸틴…“종이 호랑이” 비판 나와
-
3
멀어졌던 정청래-박찬대, 5달만에 왜 ‘심야 어깨동무’를 했나
-
4
납중독 사망 50대, 원인은 ‘낡은 보온병에 담은 커피’[알쓸톡]
-
5
“금융거래 자료조차 안냈다”…이혜훈 청문회 시작도 못하고 파행
-
6
조국 “검찰총장이 얼마나 대단하다고 5급 비서관 두나”
-
7
김병기 “재심 신청않고 당 떠나겠다…동료에 짐 될수 없어”
-
8
김경 “강선우 측 ‘한장’ 언급…1000만원 짐작하자 1억 요구”
-
9
“두쫀쿠 만드는 노고 모르면 안 팔아”…1인 1개 카페 논란
-
10
이준석, 장동혁 단식에 남미출장서 조기귀국…‘쌍특검 연대’ 지속
-
1
‘단식’ 장동혁 “자유 법치 지키겠다”…“소금 섭취 어려운 상태”
-
2
北침투 무인기 만들고 날린 건 ‘尹대통령실 출신들’이었다
-
3
단식 5일째 장동혁 “한계가 오고 있다…힘 보태달라”
-
4
한동훈 ‘당게’ 논란에 “송구하다”면서도 “조작이자 정치 보복”
-
5
파운드리 짓고 있는데…美 “메모리 공장도 지어라” 삼성-SK 압박
-
6
김병기 “재심 신청않고 당 떠나겠다…동료에 짐 될수 없어”
-
7
IMF의 경고…韓 환리스크 달러자산, 외환시장 규모의 25배
-
8
이란 마지막 왕세자 “이란, 중동의 한국 돼야했지만 북한이 됐다”
-
9
단식 장동혁 “장미보다 먼저 쓰러지면 안돼”…김재원 ‘동조 단식’ 돌입
-
10
김경 “강선우 측 ‘한장’ 언급…1000만원 짐작하자 1억 요구”
트렌드뉴스
-
1
‘건강 지킴이’ 당근, 효능 높이는 섭취법[정세연의 음식처방]
-
2
反美동맹국 어려움 방관하는 푸틴…“종이 호랑이” 비판 나와
-
3
멀어졌던 정청래-박찬대, 5달만에 왜 ‘심야 어깨동무’를 했나
-
4
납중독 사망 50대, 원인은 ‘낡은 보온병에 담은 커피’[알쓸톡]
-
5
“금융거래 자료조차 안냈다”…이혜훈 청문회 시작도 못하고 파행
-
6
조국 “검찰총장이 얼마나 대단하다고 5급 비서관 두나”
-
7
김병기 “재심 신청않고 당 떠나겠다…동료에 짐 될수 없어”
-
8
김경 “강선우 측 ‘한장’ 언급…1000만원 짐작하자 1억 요구”
-
9
“두쫀쿠 만드는 노고 모르면 안 팔아”…1인 1개 카페 논란
-
10
이준석, 장동혁 단식에 남미출장서 조기귀국…‘쌍특검 연대’ 지속
-
1
‘단식’ 장동혁 “자유 법치 지키겠다”…“소금 섭취 어려운 상태”
-
2
北침투 무인기 만들고 날린 건 ‘尹대통령실 출신들’이었다
-
3
단식 5일째 장동혁 “한계가 오고 있다…힘 보태달라”
-
4
한동훈 ‘당게’ 논란에 “송구하다”면서도 “조작이자 정치 보복”
-
5
파운드리 짓고 있는데…美 “메모리 공장도 지어라” 삼성-SK 압박
-
6
김병기 “재심 신청않고 당 떠나겠다…동료에 짐 될수 없어”
-
7
IMF의 경고…韓 환리스크 달러자산, 외환시장 규모의 25배
-
8
이란 마지막 왕세자 “이란, 중동의 한국 돼야했지만 북한이 됐다”
-
9
단식 장동혁 “장미보다 먼저 쓰러지면 안돼”…김재원 ‘동조 단식’ 돌입
-
10
김경 “강선우 측 ‘한장’ 언급…1000만원 짐작하자 1억 요구”
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개



댓글 0